These notes were compiled in my first year of graduate school. These two classes cover simple to complex linear regression. Additionally, some other methods are discussed such as Logit/Probit, Causal Inference, and time-series. These other methods were only discussed in brief and require their own separate set of notes.
Reminder: These are notes and do not encompass every idea or detail associated with the concepts. They do not (and cannot) replace classes or reading the material.
Section 1: Descriptive Statistics
While simple, it is critical you understand these. It is okay if you forget (and you will), just remember to keep reviewing. It helps to walk through the formula step by step. I have provided some commentary on the rationale behind the formula in the sections below.
You should always include descriptive statistics because it convinces your audience that they care. And it provides a guide to interpreting later analysis.
Mean (Average)
\[
\bar{x} = \frac{\sum_{i=1}^{n} x_i}{n}
\]
Above is the formula for mean (average).
Median
\[
\text{Median} = \begin{cases} x_{\frac{n+1}{2}} & \text{if } n \text{ is odd} \\ \frac{1}{2}(x_{\frac{n}{2}} + x_{\frac{n}{2} + 1}) & \text{if } n \text{ is even} \end{cases}
\]
Don’t worry about knowing this formula. Arrange everything in order. Select the middle number.
Mode
Another measure of central tendency
Mode is simply what number appears the most in our dataset.
{4,7,3,7,8,1,7,8,9,4,7}
Our mode would be 7
It appears the most.
We don’t use mode that much as a measure of central tendency but it still provides some information about the distribution.
The average of the squared differences from the Mean.
Variance is a measure of SPREAD.
Let’s walk through the formula step by step.
The \(\Sigma\) means to sum all the values together.
\((x_i - \bar{x})\)
in this part we are taking each observation and subtracting it by the mean (average).
Now lets add the square term. \((x_i - \bar{x})^2\)
Why do we square this?
Imagine a number line from 0 to 100. We have some dataset where the mean is 50. Now let’s say one of our observations is 38. 38-50 = -12. See what happens!? We have a negative number. All observations to the left of our mean are negative while all observations to the right of our mean are positive.
When we add these all up without the square term, we get ZERO!
Thus we square to accommodate for these canceling out.
There are other reasons we square but they aren’t relevant here and this is the main reason.
Now the \(n-1\)
N represents the number of observations.
Why are we subtracting it by 1?
If we were calculating the population variance, then we wouldn’t subtract by 1. However, we are pretty much never working with the population. We are always using some samples.
This part is not super intuitive. BUT, we are using the sample mean, NOT the population mean to calculate the variance.
We don’t know what the “true” population mean is. We have an estimate of it using our sample. Thus, there is some uncertainty around the sample mean (we don’t know if the sample mean is = to the population mean). To account for this uncertainty we add a -1 to our denominator.
By subtracting 1 from the denominator this makes the spread a little larger to account for that uncertainty. Think about what happens when we make our denominator smaller compared to if we don’t. Example:
\(\frac{16}{4-1}\) vs. \(\frac{16}{4}\)
the one with the \(4-1\) denominator will have a larger output and thus account for the uncertainty in our measurement.
Standard Deviation
\[
\text{Sample Standard Deviation} (s) = \sqrt{\frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n-1}}
\]
Standard deviation is denoted by \(s\) or \(\sigma\) (lower case sigma).
Standard deviation represents how far the numbers are from each other.
Look how similar this equation is compared to the variance equation.
The standard deviation is the square root of the variance!
I won’t explain the whole formula again.
I will explain why we square root the equation
We take the square root to put the output back into its original units. Our output is in the same units as the mean.
Have a good understanding of standard deviation THEN understand standard error.
OK, so what is the difference between standard deviation and standard error?
Standard deviation quantifies the variation within a set of measurements. (singular)
Standard error quantifies the variation in the means from multiple sets of measurements. (multiple)
What is confusing is that we can get standard error from one single measurement, even though it describes the means from multiple sets. Thus, even if you only have a single set of measurements, you are often given the option to plot the standard error.
Why do we take the square root of observations in the denominator?
By dividing by the square root of the sample size, we’re essentially adjusting for the fact that the standard deviation of the sampling distribution of the mean tends to decrease as the sample size increases. This is due to the Central Limit Theorem, which states that the sampling distribution of the sample mean becomes approximately normal as the sample size increases, with a mean equal to the population mean and a standard deviation equal to the population standard deviation divided by the square root of the sample size. (chat gpt gave me this and it is a kick ass explanation)
It is because of this that standard error gets smaller when we have more observations!
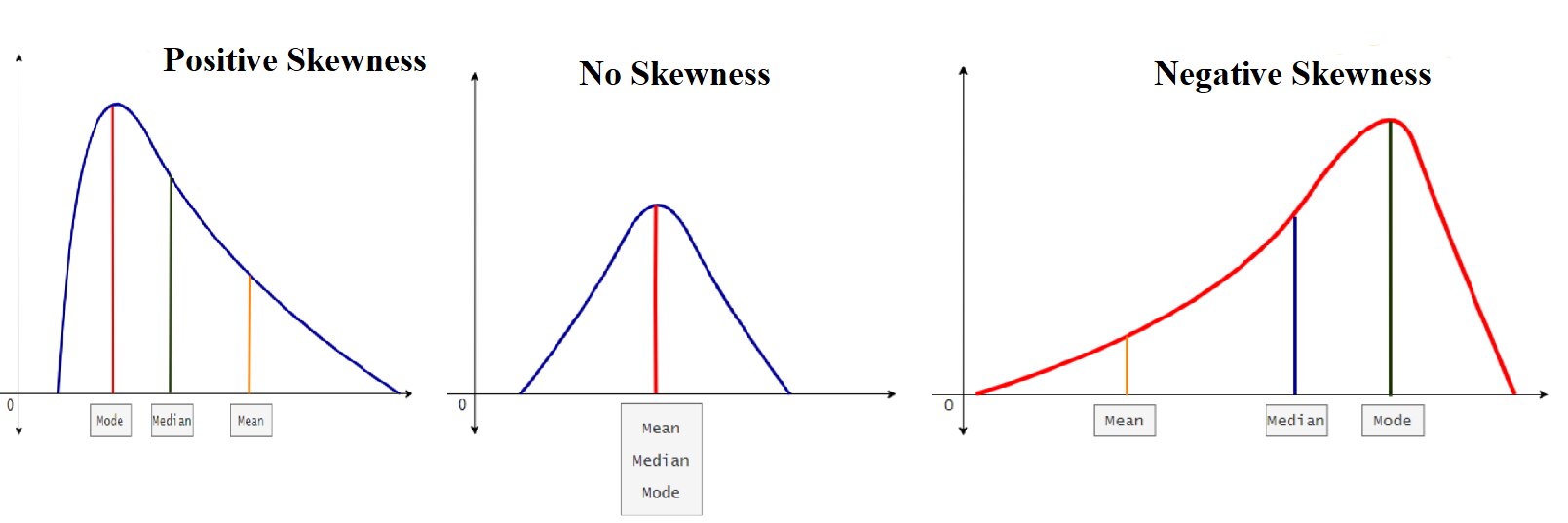
Skewness
You do not need to know the formula. You just need to know what skewness looks like and how to properly identify when your data is skewed.
When our distribution has no skew, the mean, median, and mode are all the same value.
Skewness Visualized
Positive skewness is also called “right skew”. Notice where the mean/median/mode are.
Negative skewness is also called “left skew”. Notice where the mean/median/mode are.
A measure of how much two random variables vary together
Similar to variance BUT covariance deals with two variables.
Let’s walk through the formula.
The numerator tells us to take the sum of each observation minus its mean for both variables (x and y). Then multiply.
Remember we divide by N-1 because we are using the sample means and not the population means. Thus we have a bit of uncertainty. By subtracting 1, it makes our denominator smaller and subsequently the output larger, representing the greater uncertainty.
The output of covariance is a number that tells us the direction of how these two variables vary together.
It does not tell us the strength of the relationship between the two variables.
Look how similar this formula is compared to the variance formula!
Covariance is influenced by the scale of the variables.
This formula looks scary! It actually is super simple!
Does the numerator look familiar? Look back at the covariance formula! The top IS covariance!
The denominator looks familiar too! It is the standard deviation for x and y.
Correlation is similar to covariance but it is more useful.
We interpret correlation from -1 to 1.
-1 represents a perfectly negative correlation
This will almost never happen
1 represents a perfectly positive correlation
this will almost never happen.
Correlation tell us the direction and strength of a linear relationship between two variables.
Correlation is covariance divided by the product of the two variables standard deviation. So they measure the same thing but one belongs to [-1,1] and the other (covariance) take any value.
Section 2: Statistical/Hypothesis Testing
Can we believe this finding? Is this a real relationship? Hypothesis testing helps us answer those questions. There are different types of tests we can do. Below are the “basic” tests. More complicated models will use these tests in some manner. For example, Ordinary Least Squares (OLS) uses a t-test to help us understand whether the relationship (the beta) is statistically significant.
These test correspond with a specific distribution a.k.a a probability distribution. A probability distribution TK
When we use these tests, we are using their respective probability distributions.
What is a Test Statistic?
A value that assesses how far the sample result is from what we would expect if the null were true. There are different test statistic values. They vary based on the data we are using. There is a z-score, t-test, F-test, \(\chi^2\) test. The most common for us will be the t-test, which is what we use in regression.
t-Test
Probability Distribution:
Purpose:
Uses:
\(\chi^2\) Test
Purpose:
Uses:
Analysis of Variance (ANOVA) Test
Purpose:
Uses:
F-Test
Purpose:
Uses:
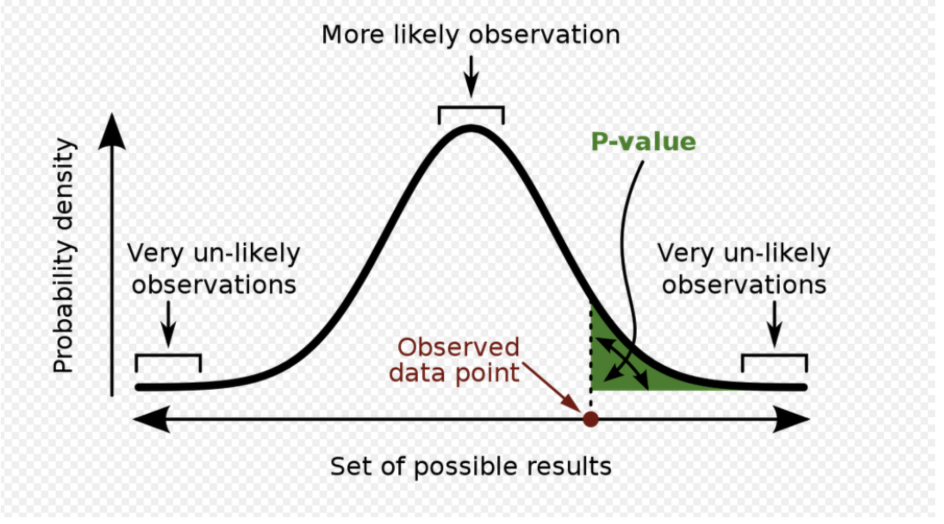
p-value
Read very closely! So many people misinterpret this concept!
Definition:
A p-value is the probability of observing a test statistic value equal to or more extreme than the value you computed if the null were true.
Alternatively, the p-value is the probability of making a type I/II error.
Purpose:
If we assume the null hypothesis is true, then we could draw the sampling distribution centered around zero. By specifing the null hypothesis we can invoke the central limit theorem.
P-values help us determine how statistically significant our relationship is. Remember that we are using data we have to tell us about data we do not have.
Uses:
The p-value is decided by the researcher. Convention typically sets the p-value at .10 and below. However, .10 is still not ideal, the lower the better.
Important Notes:
the p-value does not tell us anything substantive. It simply tells us if something is statistically significant.
Section 3: Regression Overview/Review
The big kahuna. There are other methods but regression is perhaps the most important. It is easy to understand, straightforward, and powerful. Your ability to understand it inside and out will make you smarter in every way. You are Tony Stark and regression is your Iron Man suit.
This assumption is for the purposes of constructing a hypothesis test.
We don’t need this to estimate our beta.
But by assuming the errors are normally distributed then we can run a hypothesis test (t-test) to see if we accept or reject the null hypothesis of beta = 0.
Assumption 2: \(E[\epsilon_i]=0\)
The distance between the observed and fitted line is zero. (the residual is zero)
This rarely happens BUT we estimate our \(\hat{\beta}\)’s so that the error is as close to zero as possible.
The goal is to have a line of best fit that does this for all observations.
Assumption 3: \(Var(\epsilon_i)=\sigma^2\)
This is homoscedasticity (or no heteroskedasticity).
Assumption 5: \(x_i\) is fixed in repeated sampling
X values are independent fo the error term
Assumption 6: Sample regression model correctly specified
Our sample regression equation correctly identifies the variables in the theoretical population regression model.
We include all relevant confounding variables.
No omitted variable bias.
Assumption 7: \(Cov(\epsilon_i,x_i)=0\)
covariance between residuals and parameters is equal to zero
Assumption 8: Parametric Linearity
Linear in the parameters.
We do NOT raise the betas to a power.
We can raise the variables (x’s) to a power and it remains linear.
Note: Logit models add a “link function”. This line is not linear but it is still a linear relationship.
Assumption 9: \(x_i\) must vary
Duh. You can’t do anything if your X variable doesn’t vary.
Assumption 10: n > k
This relates to degrees of freedom.
We need more operations than we have parameters or else we do not have enough information to test a relationship.
Assumption 11: No perfect multicollinearity
We wouldn’t include a column for male and a column for female because that would be perfect multicollinearity.
Multicollinearity is not a big issue (it is natural there will be some level of collinearity between our variables).
BUT perfect multicollinearity is bad and we do not want it.
Multicollinearity can (in some cases) disappear as we increase the number of observations.
This is easy to see in matrix algebra or an excel sheet.
Assumptions (Matrix Notation)
Note: These assumptions are the EXACT same assumptions listed above. The difference is in notation. Why do we do this? I answer this later, but basically its a different way to write math that is more concise and easier to understand. We use matrix algebra/notation because as our model gets bigger, scalar notation gets more complicated to read/keep track of.
Why do we bold letters? Bold letters represent matrices.
The model specifies a linear relationship between y and X
Do not raise the \(\beta\) to a power.
Assumption 2: Full rank
X is an n x K matrix with rank K
There is no exact linear relationship among variables
Sometimes called the “identification condition”
What is “rank”?
It is the number of linearly independent columns
If the number of independent columns is equal to the total number of columns then the matrix is full rank.
This assumption relates to the scalar assumption of no perfect multicollinearity.
Assumption 3: Exogeneity of the independent variables
The independent variables contain NO predictive information about
The expected value of is not a function of the independent variables at any observation (including i):
\(E[\epsilon_i|x_{j1},x_{j2},...,x_{jK}=0\)
\(E[\epsilon_i|\textbf{X}]=0\)
What does this mean?
The independent variables are not influenced by the error term or any other unobserved factors in the model.
The X variable does not depend on the Y variable (reverse causality). We can’t have the Y variable influencing our regressors (that would be endogeneity)
We can fix it. But homoscedasticity is always preferable.
These two assumptions can be written mathematically into one single assumption using matrix algebra:
The off-diagonal (the zeros) represent autocorrelation
if these are not zero (or at least very close) we have autocorrelation
The main-diagonal (the variance) represents our homoscedasticity assumption
If these values along the main diagonal are not the same or at least very close, then we have heteroscedasticity.
Assumption 5: Data generation
The data generating process of X and \(\epsilon\) are independent.
X is generated by a non-stochastic process
this assumption allows us to say “conditional on X”
This assumption is a bit confusing to me.
From my understanding, we want our X values to be fixed. We then take samples to see how our y values vary based on the fixed values of X.
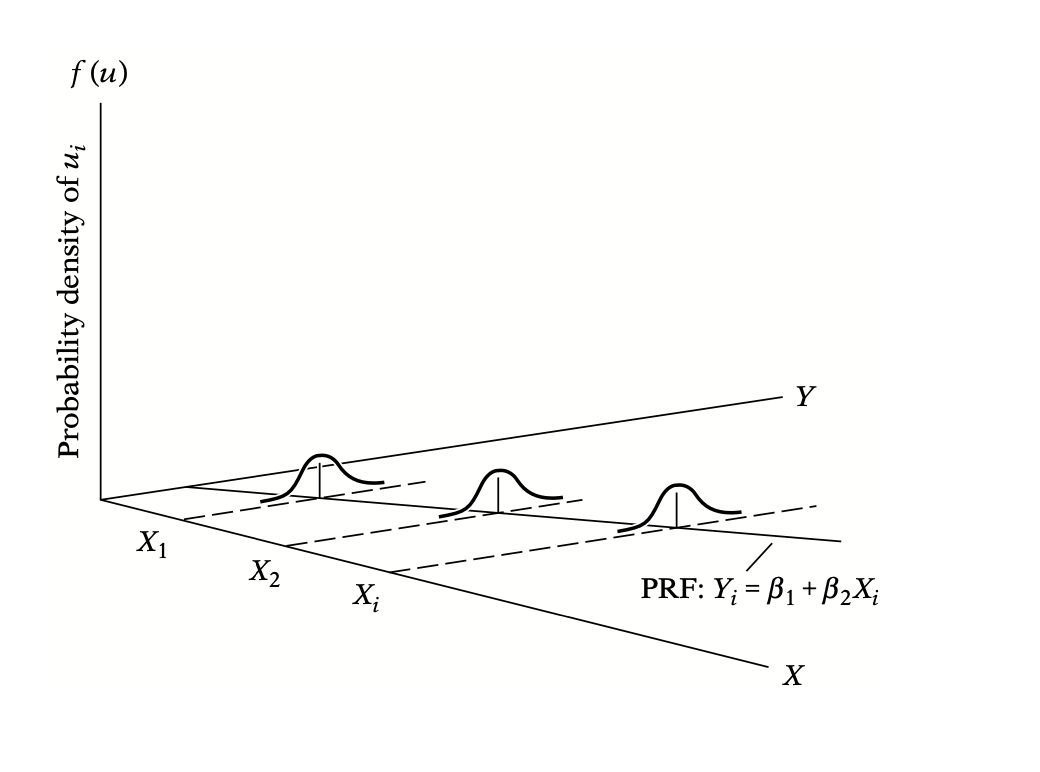
Let’s say you want to predict annual income based on years of experience. Your manager gave you three lists of employees with their annual income. Each list corresponds to a particular experience level — let’s say 3 years, 6 years, and 10 years of experience respectively. Each list contains data on 50 employees. As you can see, the x-values are fixed(3, 6, 10), but have repeated samples (50 data points per sample). This is what is known as Non-stochastic regressors
Assumption 6: \(\epsilon\) is normally distributed
This is useful for constructing our hypothesis tests and test statistics
Technically, we don’t need this for estimating our beta, just uncertainty surrounding it.
Formula for deriving \(\beta\)
Problem: We have two missing terms, 𝜷 and 𝛆. Knowing one of these will tell us the line. But since we don’t know either of these terms, how do we find it out?
We have to solve for beta. Solving for beta in Ordinary Least Squares (OLS) requires us to find a line of best fit that minimizes the unexplained difference (the error).
To do this we take the sum of the squared residuals
It may help to understand this through the formula of the residual.
First the residual is the amount our actual observed value differs from the predicted value (This is in matrix notation).
\((y-\textbf{X}\beta_0)\)
y is our observed value and the \(\textbf{X}\beta_0\) is our predicted value (the line of best fit).
WE SQUARE THIS! SO NOW:
\((y-\textbf{X}\beta_0)'(y-\textbf{X}\beta_0)\)
The (’) means transpose. It is matrix notation that allows us to multiply these two matrices (vectors).
Why do we square?
We square the residuals for a bunch of reasons. Mainly: if we don’t, the residuals (Both positive and negative) cancel out.
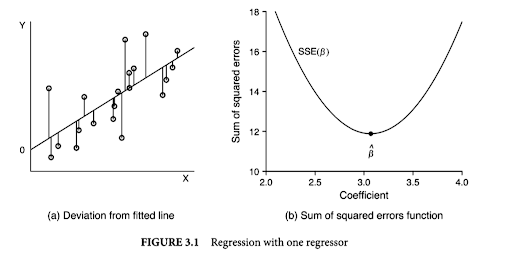
SO NOW: we want to find a line \(\hat{\beta_0}\) such that the derivative (the tangent) is set to 0 aka the minimum, hence LEAST squares. Remember, we do not know the Beta.
We set to zero to find the critical point (the minimum)
Taking the partial derivative with respect to beta, you’re essentially finding the point where the error function is not changing with respect to changes in beta. Where the slope of the error function with respect to beta is zero.
Figure b is a visual representation of what this looks like when we set our minimum. We are finding the tangent line of the function that is equal to zero!
The formula is
\(\hat{\beta}=(\textbf{X'X})^{-1}\textbf{X}'y\)
this gives us the line of best fit. This is the formula R uses to calculate the beta/line.
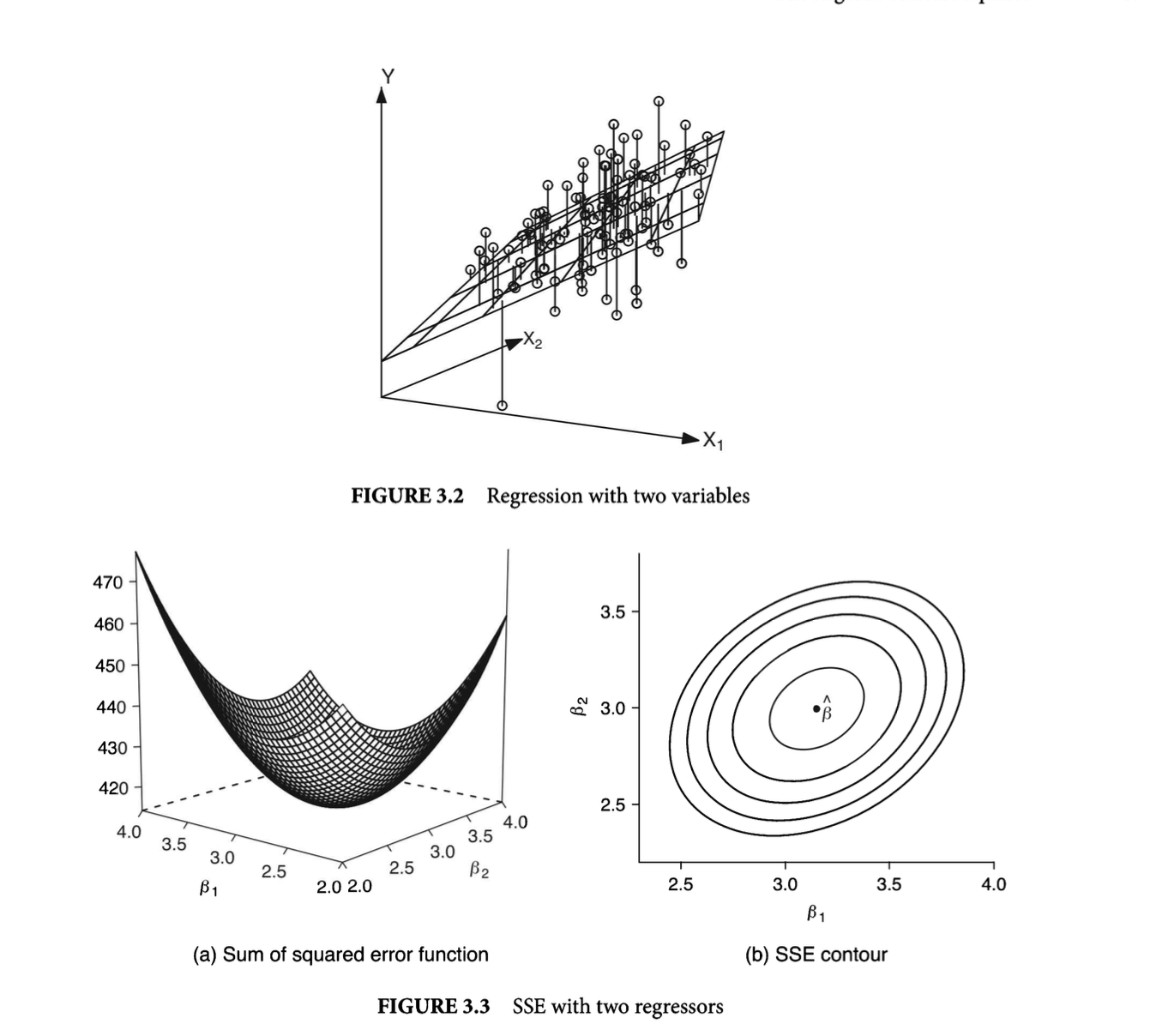
Controlling for other variables:
Compare figure 3.3 to figure 3.2. They are the same thing. However in 3.3 we have added an additional dimension because of the additional variable. What we are doing remains the same however we now just have more dimensions and we are still trying to find the minimum of that parabola(?) plane(?)
Controlling for other variables:
A bivariate regression is not a causal model. If we want to know the effect of some variable on Y, then we need to know what other factors might be confounding this relationship. Thus, we move from a bivariate to a multi-variate regression.
Frisch-Waugh-Lovell (FWL) Theorem
The FWL theorem can help explain some of the intuition of what is going on when we have a multi-variate regression. Imagine we have some multivariate regression:
\[
Y=β1X1+β2X2+⋯+βkXk+u
\]
We can simply run the full regression, but the FWL states we can get the same coefficient for \(\beta_1\) using the FWL. Again, the FWL is not something you use as an alternative estimation method to regression (you could but that’s not the point of it), but it shows the intuition behind what is happening with our main variable and other controls.
The FWL shows we can derive \(\beta_1\) through three smaller steps:
FWL: Step 1
Regress Y on all other X’s except\(X_1\) and collect the residuals. Recall residuals are the difference between our line of best fit (the predicted value) and our actual observation. Basically, how much does our prediction not explain.
\[
Y=β2X2+⋯+βkXk+u
\]
We run that regression then we take the residuals of that regression:
\[
Y - \hat{Y} = \bar{Y}
\]
These are the parts of Y NOT EXPLAINED by the other controls.
FWL: Step 2
Regress \(X_1\) on all other X’s (except itself) and get the residuals. In other words, run the same regression as above but have \(X_1\) as your dependent variable.
\[
X_1=β2X2+⋯+βkXk+u
\]
We run that regression then we take the residuals of that regression:
\[
X_1 - \hat{X_1}=\bar{X}
\]
These are the parts of \(X_1\)NOT EXPLAINED by the other controls
FWL: Step 3
Now have the residuals from both Step 1 and Step 2. We take these residuals and run a regression with them. We have the residuals from step 1: \(\bar{Y}\) and the residuals from step 2: \(\bar{X}\). Thus we run the following regression:
\[
\bar{Y}=\bar{X} +\bar{\mu}
\]
When we run this regression, our coefficient for \(X_1\) will be the exact same as the coefficient in our normal multivariate regression.
FWL: Intuition
Step by step, what we just did was:
purge Y of the influence of other regressors
purge \(X_1\) of the influence of other regressors
Then we see how those “cleaned” up versions of \(X_1\) and Y move together.
This is the partial effect of $X_1 on Y aka the multiple regression coefficient.
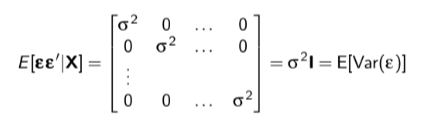
Omega Matrix
What the hell is an omega matrix \(\Omega\)?
The omega matrix is literally 𝛆𝛆’
The error times its transpose.
We obviously can’t solve this without knowing what the errors are.
This produces the variance covariance matrix (VCV) AKA covariance matrix of the errors.
Why do we care about this matrix?
We need the residuals to get our standard errors.
Additionally, this matrix is used to test our assumptions about the model. Specifically whether our model has autocorrelation and heteroskedasticity.
This is basically what the omega matrix looks like. This photo however is what we want that omega matrix to look like (ours won’t always look like that). But we want the off diagonals to be zero (or effectively zero) and we want the main diagonal to be constant.
If off-diagonal values are > 0
We have autocorrelation
If main-diagonal values are not the same at each value
We have heteroskedasticity.
NOTE: our omega matrix will NEVER be perfectly spherical.
Conversation with Andy about Omega Matrix:
I emailed Andy about this and figured it might be beneficial to include it here.
Stone:
I am looking back on your “Roll your own standard errors.r”. I see how the residual maker is part of the variance formula.
# the formula for s^2 is e’e/(n-K)
s.2 <- (t(e)%*%e)/(length(y) - ncol(X))
##I ran this code individually and it gave me a scalar. I assume this is the sum of the squared error (SSE)?
Andy:
Yes, divided by degrees of freedom, so it’s a variance
Stone:
So, autocorrelation and heteroscedasticity manifest through the variance. Then: vcv <- s.2*(solve(t(X)%*%X))
This is our VCV of the X’s and then we take the square root of the diagonal to get our SE.
We use the omega (and the assumptions of no spherical errors) to derive the equation for the SE (equation above). However, if we have spherical disturbances and use the same equation to derive our standard errors then our standard errors are wrong.
Andy:
Yes,if there are non-spherical disturbances than our standard VCV above isn’t technically correct anymore b/c the equation doesn’t simplify to that.
Stone:
Then the omega matrix (and its assumptions) is related to the population error. And thus, when we get a sample with spherical disturbances that does not match our expectations of the population error of no spherical disturbances, we then must fix it. Right?
Andy:
Right…we can’t know what the population Omega is, but we can get a good guess based off our sample Omega matrix
Stone:
So, if we switch the order, e%*%t(e) gives us the matrix of errors (WHICH IS NOT THE OMEGA MATRIX(?)). We want our matrix of errors to look like the omega matrix. It never will but we use the various tests to figure out the level of spherical errors that are present in this matrix.
Andy:
The matrix of the errors IS the Omega matrix, which is the variance covariance matrix of the errors (note the other VCV for our X’s above). It’ll never be spherical perfectly but our assumptions are about expectations so it just needs to be consistently a problem (e.g., 2 errors can be correlated, but it’s only a problem if on average there’s a correlation between errors)
Stone:
Then when we detect spherical disturbances, we purge it or do whatever (FGLS, Robust/cluster SE), which then fixes our variance and then fixes our SE? Do I have all this right? This all feels kind of magical.
Andy:
If you’re running FGLS you’re using the info in the residual Omega to adjust both your SE’s and coefficients. If you’re correcting just your SEs you’re basically adjusting the standard SE formula to account for the pattern you want to correct for.
Standard Error
Standard Errors are not intuitive to me…but they are important
Standard error is the standard deviation of the means.
The standard error quantifies the variation in the means from multiple sets of measurements.
What gets often confused is that the standard error can be estimated from a SINGLE set of measurements, even though it describes the means from multiple sets. Thus, even if you only have a single set of measurements, you are often given the option to plot the standard error.
It is an estimate!
It is worth discussing standard deviation and its formula.
The s is the standard deviation! So all that in the standard deviation formula above is IN the standard error formula.
Why are standard errors important?
Need for precision of our coefficients
How precise of a claim can we make?
We make assumptions about our standard errors.**TK
They are normally distributed.
Not a big deal.
Assuming the error term is independent and identically distributed.
Each individual error term follows the same distribution and is uncorrelated with each other.
Knowing an error term does not tell you anything about another error term.
Autocorrelation/heteroskedasticity do not bias our coefficient.
Presence of autocorrelation leads to an underestimation of the true standard errors.
Increases the possibility of making a type 1 error.
Standard errors are useful for creating confidence intervals.
Heteroscedasticity (spherical disturbances)
What is heteroskedasticity?
Non-constant error variance.
See the picture at the beginning of the document of what homoscedasticity looks like. Heteroscedasticity is the opposite of that.
Think of our errors having a pattern or they “fan out”
Using the omega matrix again, it is when each value along the main diagonal is different.
THIS AFFECTS OUR STANDARD ERROR!
How?
What does it do to our estimate?
Our coefficient is unchanged.
However the efficiency of our model is influenced.
Autocorrelation (spherical disturbances)
What is autocorrelation?
THIS AFFECTS OUR STANDARD ERROR!
How?
Interactions:
Interactions are used when we believe the relationship is conditional. For example, X causes Y, only if Z is active. The effect of X on Y depends on the level of Z. In other words, the effect of one independent variable on the dependent variable is conditioned by another variable.
To accommodate a relationship such as this one, we multiply the two variables together rather than adding. Goal: determine whether the function \(\textbf{E}[y|x]\) is constant for different sub-samples.
Interactions increase multicollinearity
THIS IS OKAY.
Include all constitutive terms
It is essential that you include the constitutive terms and the interaction in the model.
Wrong: Turnout = Age + Age*Race
Correct: Turnout = Age + Race + Age*Race
Interpretation
When interactions are dichotomous or categorical, interpretation is relatively easy. When the interaction includes a continuous variable, interpretation from the table becomes difficult.
Interpretation continued
Focusing on individual coefficients for interaction is not advisable. When a model includes interaction terms, the association between the focal predictor and the outcomes is no longer captured by a single coefficient, but rather by a combination of coefficients. See Rohrer & Bundock Models as Prediction Machines: How to Convert Confusing Coefficients into Clear Quantities.
Example Case
Let’s use the example from applied econometrics.
Let’s look at the log of wages log(inc95) as our dependent variable and education as our main independent variable. We first restrict our analysis to only females.
Call:
lm(formula = log(inc95) ~ yeared, data = subset(nlsy, female ==
1))
Residuals:
Min 1Q Median 3Q Max
-5.1738 -0.3063 0.0281 0.3476 2.0734
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.036830 0.109053 73.70 <2e-16 ***
yeared 0.145182 0.007943 18.28 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5913 on 1608 degrees of freedom
Multiple R-squared: 0.172, Adjusted R-squared: 0.1715
F-statistic: 334.1 on 1 and 1608 DF, p-value: < 2.2e-16
What does the table tell us? Recall we are only focusing on women!
Intercept: 8.036830 - This is the average of log earnings of women when years of education is 0.
yeared: 0.145182 - This is our slope. A one unit increase in years of education increases earnings by 15%.
Now let’s run the same regression but only on males.
m2 <-lm(log(inc95) ~ yeared, data =subset(nlsy, female ==0))summary(m2)
Call:
lm(formula = log(inc95) ~ yeared, data = subset(nlsy, female ==
0))
Residuals:
Min 1Q Median 3Q Max
-4.2828 -0.3398 0.0287 0.3482 1.6835
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.628191 0.090547 95.29 <2e-16 ***
yeared 0.128389 0.006577 19.52 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5932 on 2002 degrees of freedom
Multiple R-squared: 0.1599, Adjusted R-squared: 0.1595
F-statistic: 381 on 1 and 2002 DF, p-value: < 2.2e-16
What does the table tell us? Recall we are only focusing on men!
Intercept: 8.628191 - This is the average of log earnings of men when years of education is 0.
yeared: 0.128389 - This is our slope. A one unit increase in years of education increases earnings by 13%.
What is the point of these simple regressions? This becomes clear once we actually run an interaction. In this conception, our question becomes: Is the effect of education on wages, conditional on gender? We just showed that there are different estimates and intercepts for each. But what we don’t know is that if they are statistically different from each other.
m3 <-lm(log(inc95) ~ yeared*female, data = nlsy)summary(m3)
Call:
lm(formula = log(inc95) ~ yeared * female, data = nlsy)
Residuals:
Min 1Q Median 3Q Max
-5.1738 -0.3107 0.0281 0.3476 2.0734
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.628191 0.090417 95.426 < 2e-16 ***
yeared 0.128389 0.006568 19.548 < 2e-16 ***
female -0.591361 0.141812 -4.170 3.12e-05 ***
yeared:female 0.016793 0.010317 1.628 0.104
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5924 on 3610 degrees of freedom
Multiple R-squared: 0.2259, Adjusted R-squared: 0.2252
F-statistic: 351.1 on 3 and 3610 DF, p-value: < 2.2e-16
Let’s look at this carefully. You may see some numbers that look familiar!
Intercept: 8.628191 - This the average of log wages when education is 0 for MALES.
yeared: .128389 - a one year increase in education results in a 13% change in wages, for MALES.
female: -0.591361 - now hold on, this is a new number. Actually, it isn’t. Add the intercept (8.628191) to the coefficient of female (-.591361). What do you get? You get \(8.03683\)! That should look familiar because it is the intercept we estimated when we just ran the simple bivariate regression when the data was subset to only female. At yeared = 0, women earn 0.591 log points less than men.
yeared:female: 0.016793 - While it is a new number, it actually isn’t. This tells us how much the slope differs for female. The slope for male is yeared = .128389. For women, the slope is the male slope plus .016793. What does that equal? .128 + .017 = .145. Is the coefficient of .145 look familiar? It should, because that is exactly the slope coefficient we estimated in m1 earlier.
But interactions aren’t special for these reasons, they are special because they quantify whether these effects are different for each subsample. Of course, the coefficients are both different but we need to know if they are statistically different. Based off the interaction term, we see a low t-score and a high p-value, indicating that we fail to reject the null hypothesis that the effect of education on wages is the same for male and female. However, even if we have significance, it is important to plot it. Just looking at the table will not tell us where the slopes are statistically different from each other.
Section 4: Basic Questions You Are Too Afraid To Ask
What are moments?
Moments describe the probability distribution. Think of the shape of the density plot. Technically, two unique distributions could have the same mean or median. However, we need moments to help us better understand the distribution shape.
Mean
\[
\bar{x} = \frac{\sum_{i=1}^{n} x_i}{n}
\]
Median
asdf
Mode
fdsaf
Kurtosis
sadf
Why do we use matrix algebra? Scalar notation seems fine…
There are a lot of reasons. In relation to regression, matrix algebra becomes essential because doing this in scalar notation turns into hell. It is simply too hard to do all of that once you get more and more variables.
Secondly, it is how R and other coding languages calculate the coefficient. Why? Long story short, it is less taxing on your computer to do these calculations. Besides more computer sciencey explanations, your computer is doing matrix algebra all the time.
Finally, matrix algebra will be used in further methods classes. This is especially important in machine learning. You are working with an array now but in machine learning, those arrays gain more dimensions. Imagine a matrix stacked upon another matrix and another. These are called tensors. Don’t worry, you don’t have to deal with these, ever…unless you want to. TK
What is the difference between covariance and correlation?
Correlation is covariance divided by the product of the two variables standard deviation. So they measure the same thing but correlation gives an output bounded to [-1,1] and the covariance takes on the same value as the constitutive terms.
Correlation is a normalization of covariance. Covariance is hard to interpret because the scale depends on the variances of two inputs. If you see a covariance of 11,350 or 2,489, you don’t know what those mean or even which set of variables have a high correlation. Correlation divides variance out and rescales to the interval [-1, 1], so now you can make those comparisons. Correlation is covariance but has greater readability and usefulness.
What do dummy variables do to the line? Why don’t they change the slope? How come they only shift the intercept?
A dummy variable is a variable coded in binary (0 or 1). Dummy variables can be a factor (0, 1, 2, 3, etc.)
What is the difference between variance and standard deviation?
Why is Ordinary Least Squares (OLS) so powerful?
The power of OLS becomes somewhat clearer as you learn about different methods. OLS is powerful because it is extremely easy to interpret. The interpretation of OLS is easy because we are specifying a linear relationship.
OLS power comes from the popularly known Gauss-Markov assumptions. If these assumptions are met, OLS is BLUE - Best Unbiased Linear Estimator.
Despite its power, OLS has shortfalls. However, it is still important to know OLS, as many methods serve as extensions of OLS and adapt it to better fit the data.
When is OLS not good? Why use other ones?
OLS has numerous advantages. However, OLS has shortfalls that other methods can fix/correct.
OLS is not good with a categorical dependent variable.
Mediator versus Moderator
Mediator:
A mediator explains how an independent variable predicts an outcome, outlining the causal mechanism. A mediator tells us why or how something works.
Moderator:
A moderator variable changes the strength or direction of a relationship between two variables. Moderators tell us when or for whom something works. Influences the strength of a relationship. The built environment is a moderator for how people interact, it influences the nature and strength of interaction. But it does not explain how people interact.
How is standard error difference from standard deviation?
Standard deviation quantifies the variation within a set of measurements. Standard error quantifies the variation in the MEANS from multiple sets of measurements.
This gets confusing because we can estimate standard error off of one measurement.
Watch the video. Seriously, just watch the damn video.
Are the assumptions about regression related to the sample or population?
This was originally a question on Andy’s midterm. I got it wrong. :(
The assumptions relate to the population.
We test these assumptions using our sample.
We use samples to tell us what we think the true (population) relationship is.
Using data we have to tell us about data we do not have.
Variance is a measure of spread. Variance helps us understand the dispersion or variability in a data set. Variance estimates how far a set of numbers are spread out from the mean value. It can be difficult to interpret based on the output alone. This is because these values are squared, so we can’t really tell based on the number alone whether the value is relatively high or low.
Understanding variance is critical in statistics. Variance is integral to the efficiency of our estimators. That is, how accurate our model is.
Why do we care so much about standard errors?
I am having trouble visualizing OLS with many variables. What do I do?
Not much. We are pretty limited to understanding things in three dimensions. Imagine you have 8 variables in your OLS model. Try to draw an 8 dimensional model that shows the relationship. It is impossible.
Instrumental variables, what are they? Will I use them? Should I use them?
Instrumental variables are somewhat rare and frowned upon (?) in political science. To be a good instrumental variable, instrumental variables must satisfy two conditions:
The instrumental variable is theoretically relevant to x.
The instrumental variable must satisfy the exclusion restriction.
The first point requires that our instrument (z) must be endogenous to our independent variable (x)
The exclusion restriction is typically where instrumental variables get attacked. The instrumental variable (z in this case) must only affect X. Z-> X -> Y. The difficulty to this condition is that there is no statistical test. The exclusion restriction must be defended by theory.
It is very difficult to find an instrument that is both related to X and does not affect Y. An example of a good instrument is provided below (thank you ChrisP from StackExchange):
“For example, suppose we want to estimate the effect of police (𝑥) on crime (𝑦) in a cross-section of cities. One issue is that places with lots of crime will hire more police. We therefore seek an instrument 𝑧𝑧 that is correlated with the size of the police force, but unrelated to crime.
One possible 𝑧 is number of firefighters. The assumptions are that cities with lots of firefighters also have large police forces (relevance) and that firefighters do not affect crime (exclusion). Relevance can be checked with the reduced form regressions, but whether firefighters also affect crime is something to be argued for. Theoretically, they do not and are therefore a valid instrument.”
Why should we use an instrumental variable?
The need for an instrumental variable arises when we are concerned for confounding variables or measurement error.
Most of the time these suck. You need to defend them rigorously with theory and even then are hard. Rainfall is one that is used in many cases with success. If asked to use one, the classic rainfall instrumental variable might work.
Should we care about \(R^2\)?
It depends on your question. Chances are you want to find some variable (X) that causes another variable (Y). In this instance, your \(R^2\) is mostly irrelevant. You want to see whether that X variable is statistically having an effect on your Y variable. For example, my data 1 project was on the relationship between walkability and voter turnout. I wanted to see if the walkability of an area had an impact on voter turnout in 2016, 2018, and 2020 general elections. Once I accounted for confounding variables, all I cared about was the significance of my variable of interest (walkability). \(R^2\) told me nothing that helped me answer this question.
However, R^2 is very important for questions surrounding prediction. TK
Also we should focus on adjusted R^2
We are in the business of beta hats not y hats.
Everyone talks about endogeneity. What is it?!
Endogeneity is when the error term is correlated with the X. Remember that the error term contains everything not in our model (everything that determines Y but is NOT X, will be in our error term). If any of those things not in our model (the error) are related to our X and affect Y, then we have endogeneity. Endogeneity relates to confounders.
Endogeneity leads to bias in our coefficient.
What is orthogonal?
This concept was always a bit confusing as it can have different meaning in different contexts.
ORTHOGONAL MEANS INDEPENDENT
Simply put, orthogonality means “uncorrelated”. An orthogonal model means that all independent variables in that model are uncorrelated. If one or more independent variables are correlated, then that model is non-orthogonal (statisticshowto.com)
Is OLS a causal Inference model?
Why do we use the normal distribution?
Section 7: Interpretation Deep Dive
Example
Interpreting Control Variables
Our model, of whatever specification, will likely include numerous control variables. Each of these variables included will have their own coefficient estimated. Of course, we have our main IV, but should we bother to interpret the other variables in our model? No. This is known as the “Table 2 fallacy”.
Section 8: Thinking Deeper
Unbiased Inferences
“If we apply a method of inference again and again, we will get estimates that are sometimes too small. Across a large number of applications, do we get the right answer on average? If yes, then this method, or estimator, is said to be unbiased.” - KKV
Bias occurs when there is a systematic error in the measure that shifts the estimate more in on e direction than another over a set of replications. Note there is statistical bias and substantive bias.
An estimator of \(\mu\) is said to be unbiased if it equals \(\mu\) on average over many hypothetical replications of the same experiment.
Efficiency
We generally only get to estimate once. We want confidence that the one estimate we get is close to the right one.
Efficiency is measured by calculating the variance of the estimator across hypothetical replications. For unbiased estimators, the smaller the variance, the more efficient (the better) the estimator.
Bias vs. Efficiency
It is a tradeoff!
Section 9: Causal Inference
Readings Associated:
Keele, Luke. 2015. “The Statistics of Causal Inference: A View from Political Methodology.” Political Analysis 23(3): 313–335
What is Causal Inference?
Causality refers to the relational concept where on set of events causes another. Causal inference is the process by which we make claims about causal relationships. Testing causality is done under the counterfactual model, that is, causation is defined in terms of observable and unobservable events.
Why should we are about the counterfactual model and how is this different from statistics broadly?
the counterfactual approach has provided new insights in the assumptions needed for data to be informative about causality.
a renewed emphasis on research design and design-based approach.
The Fundamental Problem of Causal Inference
It is actually very difficult to say on thing actually caused another. Why? Because we can never observe the real counterfactual. We live in one universe. You cannot observe someone taking both the treatment and placebo pill. You only see the universe in which they took one or the other.
Components of Causal Inference
Identification
We say a parameter in a model is identified if it is theoretically possible to learn the true value of that parameter with an infinite number of observations. We seek to describe the conclusions that can be drawn with an infinite sample. Inference requires two components: identification and statistical. Studies of statistical inference on the other hand focus on what can be learned with finite samples. The causal identification step is important to see if it’s possible to estimate the effect of Treatment on Outcome.
Estimands
What is an estimand? You can think of them as an inquiry. However, the inquiry is the function that operates on events generated by the real world or a simulated world. The estimand is the value of that function. We use “inquiry” to refer to the question and “estimand” to refer to the answer to the question.
Average Treatment Effect (ATE): \(ATE=\mathbb{E}[Y_{i1} -Y_{i0}]\)
The ATE is the average difference in the pair of potential outcomes average over the entire population of interest.
Average Treatment Effect of the Treated (ATT): \(ATT=\mathbb{E}[Y_{i1} -Y_{i0} |D_i=1]\)
The ATE defined for the subpopulation exposed to the treatment
We might average over subpopulations defined by pretreatment covariates such as sex and estimate the ATE for females only = ATT.
Threats to Identification
Confounding due to a common cause
Confounding due to a common effect
Assumptions
Assumption of independence between treatment and potential outcomes.
The stable unit treatment value assumption (SUTVA) - Rubin 1986
there are no hidden forms of treatment, which implies that for for unit \(i\) under \(D_i=d\), we assume that \(Y_{id}=Y_i\)
AKA the consistency assumption
a subject’s potential outcome is not affected by other subjects’ exposure to the treatment.
This is a big problem and must be avoided - think of it as contamination. Your no longer looking at treated vs. control but now between a treated unit and partially treated unit.
if we have no knowledge of these spillovers, causal parameters cannot be identified.
Identification Strategies
A research design intended to solve the causal inference identification problem (Angrist and Pischke 2010). To ask what is your identification strategy IS to ask what research design (and assumptions) one intends to use for the indemnification of a causal effect.
Random Experiments
Randomize recipients of treatment. The typical estimand is the ATE (equivalent in this to the ATT).
Critical strength of experiments is that the researcher has the ability to impose independence between treatment status and potential outcomes on a set of units because they can impose a particular type of assignment process.
The researcher can assert that the treated and control groups will be identical in all respects, observable and unobserervable. EXCEPT for who got the treatment which is known.
Randomization
Randomization eliminates selection bias.
Natural Experiments
Instrumental Variables
Regression Discontinuity Designs
Selection on Observables
Selection on Observables with Temporal Data
Partial Identification
Mediation Analysis
Reasoning About Assumptions
Is OLS A Causal Inference Model?
It can be, but hinges important on the Conditional Independence Assumption (CIA). The CIA assumes that treatment status is independent of both potential outcomes. If you can argue, controlling for all these other variables, that the treatment is assigned as if random (like in an RCT), then you can argue that you do not have selection bias (or OVB) and your OLS estimate is a causal effect.
Defending your OLS as a causal
Be clear on what is not a threat.
At least sign the bias on remaining threats.
Section 9.5: Likelihood
The principle of maximum likelihood is based on the idea that the observed data (even if it is not a random sample) are more likely to have come about as a result of a particular set of parameters. Thus, we flip the problem on its head. Rather than consider the data as random and the parameters as fixed, the principle of maximum likelihood treats the observed data as fixed and asks: “What parameter values are most likely to have generated the data?” Thus, the parameters are random variables Ward and Ahlquist (2018).
TK - I think it helps to explain what we mean by parameters….
parameters ARE RANDOM VARIABLES!
mean, variance, coefficients, etc
the
Likelihood can be thought of as the join probability of the data as a function of parameter values for a particular density or mass function.
The key innovation in the likelihood framework is treating the observed data as fixed and asking what combination of probability model and parameter values are the most likely to have generated these specific data.
likelihood is the product of probability distributions, evaluated at each of our observed data points. When we select a model, we have to choose a convenient distribution for our data. Convenient distribution in this case refers to a a parametric probability distribution.
In Maximum likelihood, we specify our distrubtion based on the type of data and then we are estimating that distribution’s respective parameters. Each distribution, whether poisson, bernoulli, normal, etc. will have some parameter that describes the shape of distribution.
\(\theta=\) “the set of parameters” that define your chosen distribution.
Example: in a Normal model, \(\theta=(\mu, \sigma^2)\)
In MLE, you find the \(\theta\) that maximizes how likely your data are under that distribution.
thus, this hinges on us specifying the stochastic component correctly.
I dont really understand the iid.
Why do we need maximum likelihood?
We use it anytime our dependent variables has a distribution that was not generated by a Gaussian (normal) process. We are trying to estimate the \(\theta\) (parameter) values based on the data we have been given.
The Basic Structure of MLE
Stochastic component
Stochastic component: \(Y_i\sim f(\theta_i)\)
Here, \(f\) is some probability distribution or mass function. These can be Gaussian, binomial, Poisson, Weibull, etc. The stochastic statement describes our assumptions about the probability distributions that govern our data-generating process. The outcome needs to come from an exponential family.
What does the theory tell us about the underlying PDF?
What do the realized values, \(y_i\), tell us? (using histograms, summary stats…)
Is your random variable discrete or continuous?
Basically: know what type of data you are working with! Is this count, discrete, continuous, time till failure?
The systematic statement describes our model for the parameters of the assumed probability distribution. We characterize the systematic components by creating a vector of explanatory variables that are linear in the predictors…these are just our normal betas setup in regression. These are the factors that affect the conditional mean of \(Y_i, \mu\).
The third component (link function)
The third component which is somewhat of an afterthought compared the the previous two, is the “link function”. The link function literally links the random component with the systematic component.
Difference between MLE and OLS?
They are equivalent, and the OLS estimator can be derived under weaker assumptions. But the OLS approach assumes a linear model and unbounded, continuous outcome. The linear model is a good one, but the world around can be both nonlinear and bounded. The ML approach permits us to specify nonlinear models quite easily if warranted by either our theory or data. The flexibility to model categorical and vounded variables is a benefit of the maximum likelihood approach.
Section 10: Generalized Linear Models (GLM)
GLMS have three components: a structural component, a link function, and a response distribution
Random component: This specifies the response variable y and its probability distribution.
Linear predictor: Xb
link function: this a function g applied to each component of E(y) that relates
the link function connects the random component with the linear predictor.
THE LINK FUNCTION BOUNDS!
The link function (actually the inverse link, in an accident of naming) in a GLM fixes this up by transforming the output of the linear function to lie in the acceptable range of parameters for distribution family.
Linear Regression
Linear regression is a type of generalized linear model.
What are the advantages of the MLE approach in the case of ordinary least squares?
none, they are equivalent, and the OLS estimator can be derived under weaker assumptions. But the OLS approach assumes a linear model and unbounded, continuous outcome. Agresti (2015)
The maximum likelihood approach permits us to specify nonlinear models quite easily if warranted by either our theory or data. The flexibility to model categorical and bounded variables is a benefit of the maximum likelihood approach.
do we still estimate the betas the same though? In MLE, NO! We estimate betas my maximizing the likelihood. Partial derivative stuff and calculus.
Logit
Models the probability of an event. Dependent variable is binary (0 or 1). The logit is a cumulative density function -it can be thought of as a distribution.
Link Function:
\[
f(x) = \frac{1}{1+e^{-X_i\beta}}
\]
The link function is the cumulative density function (CDF)
Logit Interpretation
The output from the logit is the log odds value. Literally an odds ratio logged.
Odds Ratio
What is an odds ratio?
\[
Odds = \frac{Probability \ Event \ Occurs\ (p)}{ Probability \ Event \ Does \ Not\ Occur \ (1-p)}
\]
Logit Limitations
In small samples, ML estimates of logit model coefficients have substantial bias away from zero Rainey and McCaskey (2021)
you can use a penalized maximum likelihood to fix this issue.
Can We Just Use OLS?
You could. In fact, many (mostly economists) argue that this is economical and won’t be too much different.
Linear interpretations of betas
simple
Works well if \(X_i\) is also distributed Bernoulli
Problems:
impossible predictions
TK
Probit
Probit is a different model but is used for exactly the same purposes when our dependent variable is dichotomous. So what is the difference? The probit uses a different link function.
more flexible -
Probit Interpretation
Logit over Probit?
Which one should we use? To be honest, I haven’t seemed to find a good answer to this. They are both nearly identical in results. However, the logit is considered the canonical link function, and thus has considerably more resources on it. Additionally, the logit uses the log of odds-ratios for interpretation.
Aside from greater resources available for the use of the logit, it seems the logits popularity might also be a result of it’s coefficients being larger than probits. It is not that logit estimates a different true effect, it’s just that the coefficient is higher because of the units our estimation is using. While it is not actually bigger, it gives the appearance of being bigger. Perhaps the best reason I can give for its’ use is that bigger = better.
Section 11: Model Selection
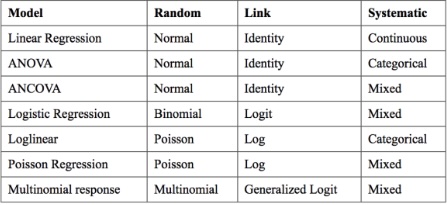
This section is intended for application purposes. What model do we used based on our data and application purpose? The bulk of this decision is driven by the structure of our data, specifically the dependent variable.
The table above is useful because it defines most of what we do once we specify the stochastic component (the dependent variable). The random component specifies the data-generating distribution. Once you specify the random component, you are essentially saying, “I believe \(Y | X\) comes from this exponential-family distribution.” Once this is selected, we are essentially furnished with a link to connect the random to the systematic component. Where does this link come from? It comes from super nerds in statistics back in the day that have already done the math to solve it. These link functions are the canonical link functions, meaning they are the “default” link functions. However, this should not mean that you are restricted to these link functions. For example, while logit is the canonical link function for the binomial distribution, there is also the probit that can be used.
Ordinary Least Squares (OLS)
2 Stage Least Squares this is an instrumental variable
Logit
Probit
Negative Binomial
Poisson
Multinomial Logit
Ordinal Logit
Section X: Bias
What is Bias?
Bias is
Where does bias show up?
Bias relates to our coefficients (\(\beta\))’s!
Types of Bias:
Selection Bias
As social scientists, we are interested in making causal arguments, our X causes variation in Y. In reality, when we use data, we have some variable of interest and a list of theorized control variables. We can think of our variable of interest as the treatment. However, we are not assigning our treatment randomly; there are likely specific (or latent) factors of a person that may influence their likelihood to receive the treatment. In this case, our treatment is not randomly assigned.
Let’s use an example from my own study. I am interested in the effects of a walkable environment on voting turnout. I wan’t to make the case that living in a walkable area causes people to vote more. However, I cannot randomly assign people to live in walkable or non-walkable areas. People can self-select (for the most part) where they want to live. I have data on people’s voting history and where they live. I decide to a run a regression with voter turnout as my DV and the walkability of where they live as my IV, with an assortment of related control variables. I find a positive association, thus, living in a walkable area causes people to turnout to vote at a higher rate, right? No, what I have described is textbook selection bias occurring. My treatment (walkability of an area) is not randomly assigned. People can move for a variety of reasons. Maybe there is something about people wanting to live in a walkable environment (self-selecting) and being more likely to vote. Thus our estimate we derived earlier is biased as it does not account for people self-selecting into the treatment.
To make a causal argument, we need to make sure that our potential outcomes are independent of the treatment status so that we can argue that we have no selection bias (this is the CIA). Randomization ensures the treatment status is independent of our observation’s untreated outcomes. This is possible in a randomized control trial (RCT), but when we can’t do an RCT, we rely on our data. If we can argue that our treatment assignment is independent of our variables, then we can make a causal argument.
Omitted Variable Bias (OVB)
Remember that we are trying to estimate the effect of some X on Y. However, if we do a simple regression, and say this is the effect of X on Y, then we are likely engaging in an OVB. Basically, OVB occurs when you are missing an important control variable. Your regression is mis-specified.
OVB biases our coefficient on a number line. It is always positive or negative.
Signing the bias
Signing the Bias Table
\(Corr(x_1,x_2)>0\)
\(Corr(x_1,x_2)<0\)
\(\beta_2>0\)
positive bias
negative bias
\(\beta_2<0\)
negative bias
positive bias
This table helps to understand what variables you should control for. Just because a variable influences our dependent variable, does not mean you need to control for it. If that were the case, we would need to basically include a million variables. We only need to control when that variable influences our DV AND correlates with our main independent variable of interest. In simple terms, OVB is just not including the right control variables which causes a mis-specification of our regression.
The direction tells us how our OVB is influencing our coefficient between our main independent variable and our DV.
Section X: What influences our Standard Errors?
Section X: Panel Data
Section X: Econometrics Midterm Review 1
This section is to review the questions and my answers on the midterm. I provide my (mostly) incorrect answers and then provide the updated (correct) answer.
Question 1:
Part a:
Part b:
The researcher then adds a quadratic term and runs the following regression:
The estimates are\(\hat{\beta_1}=2.4(1.1)\)and\(\hat{\beta_2}=.12(.06)\)with standard errors in parentheses.
Question: Interpret the magnitudes of these coefficients, ignoring whether they are statistically significant and continuing not to use causal language.
Original Answer: 5 points available only received 1 point.
A one unit increase in particulate matter is associated with a 2.4 unit increase in asthma hospitalizations. Magnitude is substantial.
Corrected Answer:
\(\beta_1\) represents the effect of particulate matter on Asthma hospitalizations in 2024. On average, a one unit increase in particulate matter is associated with 2.4 more hospitalizations per 100,000 residents in 2024. Given our independent variable is measured in micrograms per cubic meter, the effect of a one unit increase resulting in 2.4 more hospitalizations on average appears substantial.
\(\beta_2\) is the quadratic term. We make this functional form change if we believe the effect of X on Y is not constant. That is, the effect might decrease or increase at certain points. Adding the quadratic term allows us to test this specification. Our \(\beta_2\) coefficient is .12, this means for every one unit change in annual particulate matter, the effect of particulate matter on hospitalizations increases.
Ignoring the intercept, we get a value of 3.6. Thus, when X is 5, the expected value of hospitalizations increases by 3.6 units. If we did this at different levels of X, we will get different slopes, indicating that as X increases, the rate of hospitalizations increases.
X=0 -> slope is 2.4
X=5 -> slope is 3.6
X=10 -> slope is 4.8
Question: (4 points) The regression results list a t-stat of 2.00 and a p-value of 0.0455 in the for for \(\beta^2\). Explain the meaning of the null hypothesis being tested and what the researcher should conclude based on a p-value of 0.0455.
Original Answer: 4 points available; received full credit
The null of our quadratic term is simply a linear form. Our alternative hypothesis is our quadratic is not linear. Given our t-score + p-value, our quadratic term is significant at the .05 level. We can reject the null hypothesis. Our quadratic is not linear.
Corrected Answer:
I received maximum points but I want to expand a little. What does this mean in plain english? Basically, this question is asking, as X grows, does the slope marginally increase? Is the effect linear (a straight upwards line) OR does the effect curve up (the slope getting steeper as X increases - think of a hill)? Our result here indicates that it is the latter. As particulate matter increases, the effect on hospitalizations grows marginally bigger. The effect accelerates as X increases. It is convex.
Question: (2 points) Name a specific variable you think the author should add as a control variable to address omitted variable bias. When describing the variable, remember that the observations are counties.
Original Answer: 2 points available; received full credit
Areas prone to wildfire. More wildfires can increase who goes to hospital for asthma treatment. More wildfires increase particulate matter.
Question: Make an argument for the sign of the bias on \(\beta_1\) in the short (bivariate regression when leaving out the variable you named in the previous question.
Original Answer: 4 points available; received 3/4 points
Given both are positive, we are observing a positive omitted variable bias.
Note: this control sucks and sounds more like an instrument
Correct Answer:
There are two things we are doing here:
1) finding an omitted variable
2) signing the bias of the omitted variable
Let’s first identify a better control variable that we are omitting. I chose wildfires in a panic. How do we think of a control variable? What is a variable that influences asthma hospitalizations AND correlates with annual particulate matter? One that comes to mind is TK
Question 2:
Consider a randomized controlled trial (RCT) evaluating whether an intervention that deletes streaming video apps from students’ phones improves their grades. Before agreeing to be in the study, students need to give their phone pin to the research team and to give them permission to uninstall apps. If they are randomized into the treatment group, the researchers uninstall all streaming video apps from the student’s phone and install software to make sure that the student does not re-install the apps or access streaming video through the website. Students in the control group read a handout about how streaming video re-wires people’s brains to focus on shorter term psychological rewards, but the researchers do not adjust anything on the control group’s phones. The main outcome is the end-of-semester GPA, measure on a 4.0 scale.
Part a:
Before the RCT, student success center offered students the ability to receive this service on a voluntary basis. A researcher considers using administrative data to determine the effect of this service. Specifically they consider comparing students’ average grade in semesters when students opted in to the service to the students’ own average grades from the semester before they opted in.
Question: (5 points) Explain why this comparison is unlikely to give the causal effect of the streaming video deletion intervention.
Original Answer: 4/5 points received.
We have a selection bias as individuals opted into the service. This means the treatment assignment was not random. The endogenous treatment assignment biases our results results because there is likely some features about a person that opts in that makes them systematically different from those that do not.
Also, the previous semester was different classes. Comparing two different semesters is problematic because it does not give us an appropriate conterfactual.
True or False Section
Question 3:
True or False: Even if study participants can select whether to participate based on the gains they would experience (so that \(E[Y_{1i} - Y_{0i} | D_i =1] \neq E[Y_{1i} - Y_{0i} | D_i =0]\)), is it possible for the difference in mean observed outcomes for the treated and untreated groups (\(E[Y_{i}| D_i =1] - E[Y_{i}| D_i =0]\)) to have a causal interpretation.
Section X: Causal Inference
With a working understanding of different statistical models, we move to the land of causal inference. It is important to note here that while causal inference gets treated as a separate enterprise, it is not. Causal inference is a paradigm and framework we use in tandem with our statistical models to make causal claims about the world. If your econometrics training is like mine, you have probably learned about all these models and how they help you understand how X relates to Y conditional on a bunch of other variables (Z). But you’ve been told the effect of X is still not causal.
Section X: Robustness Checks
Section X:
Lean towards being opinionated
don’t hedge.
Section X: Confidence Intervals
What are they?
In both cases the width of the confidence interval is proportional to the standard error of the estimator. That is, the larger the standard error, the larger is the width of the confidence interval. The larger the standard error of the estimator, the greater is the uncertainty of estimating the true value of the unknown parameter. Thus, the standard error of an estimator is often described as a measure of the precision of the estimator. (how precisely the estimator measures the true population value).
The confidence interval gives us the set of all null hypotheses that we would have been unable to reject. To get the 95% confidence interval, you simply add and subtract 1.96 standard errors to your estimated coefficient. 99%? Just add/subtract 2.33 standard errors to both sides.
Data from a representative sample were used to generate a 95% confidence interval for the proportion of female babies born each year. The result yields an upper bound of 0.56 and a lower bound of 0.48. This 95% confidence interval is reported as 95% CI (0.48, 0.56). Associatively, there is a 95% confidence level that this interval will contain the true population proportion.
Informally, a confidence interval (CI) is a range of values (aka an interval) which is likely to contain a population value (aka a parameter) for “something” that is being estimated. This interval contains/surrounds what is known as an estimate (aka a point estimate). Ideally, a narrow confidence interval (CI) if desirable because it conveys a better estimation of the actual population value.
Why don’t econ papers report t-stats and p-values sometimes? They only care about the coefficient and SE - they can derive the rest fairly easily with those two values.
References
Agresti, Alan. 2015. Foundations of Linear and Generalized Linear Models. John Wiley & Sons.
Rainey, Carlisle, and Kelly McCaskey. 2021. “Estimating Logit Models with Small Samples.”Political Science Research and Methods 9 (3): 549–64.
Ward, Michael D, and John S Ahlquist. 2018. Maximum Likelihood for Social Science: Strategies for Analysis. Cambridge University Press.